本文讨论如何使用python的pytagcloud模块制作中文标签云图片和html文件。
如果你只是为了搜索到如何用python制作中文标签云,请跳过缘起和爬取文本数据部分从标签云部分看起:
缘起
- 学习scrapy,顺便就拿byr做了实验,异步强大的吞吐能力看的目瞪口呆。看到scrapy官网说到scrapy就是抽取网页中的元数据用以数据分析等作用,想了想就做做版面标签云分析吧。
- 另一方面,R语言课上老师讲到文本分析,R语言那些包对中文的支持真是不错。为什么Python没有支持中文的包呢?我试着搜索了下,都是提问如何使用的而没有任何具体解决方案。不由得感慨还是R的社区在文本分析领域活跃。
爬取文本数据
首先要获取生成标签云的原始数据。什么都行,直接拿篇中文文章都可以,不过我这里是爬取byr论坛某些板块的标题数据。
scrapy从网页抽取数据的能力相当强大,我在这里第一次体验到了xpath的方便之处,从此,即使是一些简单的网页任务也会用lxml来使用xpath。
在firebug里简单分析下,然后一页一页地请求网页然后抽取标题。再合成一个单独的文本。
标签云部分
需要以下先决条件:
确保安装pytagcloud,pip会顺便帮你帮它的依赖都装上
pip install --user pytagcloud准备一个中文字体文件比如
simhei.ttf安装中文分词模块jieba
pip install --user jieba
然后,为了生成中文标签云,我们要分几步:
首先,把你的文本进行分词,并生成一个以单词为键以单词出现频数为值的字典。顺便去掉没有意义的词语比如“的”,“一个”这种。
wg = jieba.cut(YOUR_TEXT, cut_all=True)
wd = {}
nonsense = [u"一下", u"什么", u"一个"]
for w in wg:
if len(w) < 2:
continue
elif w in nonsense:
continue
try:
str(w)
continue
except:
if w not in wd:
wd[w] = 1
else:
wd[w] += 1
其次,如果字典太大pytagcloud会报错:
IOError: unable to read font file '/home/reverland/.local/lib64/python2.7/site-packages/pytagcloud/fonts/simhei.ttf'
另外,一个标签云图片上也不需要太多词语。所以我们对词语出现频数排序,然后选取前50
from operator import itemgetter
swd = sorted(wd.iteritems(), key=itemgetter(1), reverse=True)
swd = swd[1:50]
接下来就可以参见pytagcloud再github主页上说明生成tag数据:
tags = make_tags(swd,
minsize=SIZE1,
maxsize=SIZE2,
colors=random.choice(COLOR_SCHEMES.values()))
但此时pytagcloud还不支持中文字体,我们需要添加一个中文字体。
然后把你准备好的中文字体文件simhei.ttf移动到~/.local/lib64/python2.7/site-packages/pytagcloud/fonts/下,并更改其下的fonts.json文件,比如在头部添加一条记录:
[
{
"name": "SimHei",
"ttf": "simhei.ttf",
"web": "none"
},
......
现在,生成标签云png图像:
create_tag_image(tags,
'tag_cloud.png',
background=(0, 0, 0, 255),
size=(900, 600),
fontname="SimHei")
你将在当前目录下发现一个名为tag_cloud.png的标签云图片:

注意:参数SIZE1和SIZE2可能需要反复试验才能找到合适的。
现在,继续讨论如何生成html格式的标签云,html格式的标签云不会出现图片中有横有竖的情况。更多细节参看pytagcloud在github上的源码中测试文件。
在我们已经通过make_tags生成标签数据之后,生成html数据:
data = create_html_data(tags,
size=(900, 600),
layout=3,
fontname="SimHei",
rectangular=False)
还要准备个模板文件来生成html文件,比如template.html,关键别忘了指定语言和编码让浏览器能正常识别:
<html lang="zh_CN">
<head>
<meta charset="UTF-8">
<title>PyTagCloud</title>
<style type="text/css">
body{
background-color: black;
}
a.tag{
font-family: 'SimHei', 'Sans';
text-decoration: none;
}
li.cnt{
overflow: hidden;
position: absolute;
display: block;
}
ul.cloud{
position: relative;
display: block;
width: ${width}px;
height: ${height}px;
overflow: hidden;
margin: 0;
padding: 0;
list-style: none;
}
$css
</style>
</head>
<body>
<ul class="cloud">
$tags
</ul>
</body>
</html>
将其读入并转化为模板
from string import Template
with open(template_filename) as f:
html_template = Template(f.read())
准备填充进去内容的字典:
context = {}
tags_template = '<li class="cnt" style="top: %(top)dpx; left: %(left)dpx; \
height: %(height)dpx;"><a class="tag \
%(cls)s" href="#%(tag)s" style="top: %(top)dpx;\
left: %(left)dpx; font-size: %(size)dpx; height: %(height)dpx; \
line-height:%(lh)dpx;">%(tag)s</a></li>'
context['tags'] = ''.join([tags_template % link for link in data['links']])
context['width'] = data['size'][0]
context['height'] = data['size'][1]
context['css'] = "".join("a.%(cname)s{color:%(normal)s;}\
a.%(cname)s:hover{color:%(hover)s;}" %
{'cname': k,
'normal': v[0],
'hover': v[1]}
for k, v in data['css'].items())
得到要生成的html文件并写入:
html_text = html_template.substitute(context)
with open('tagcloud.html', 'w') as html_file:
html_file.write(html_text.encode('utf-8'))
在当前目录你会得到一个名为tagcloud.html的文件,用浏览器打开如下:
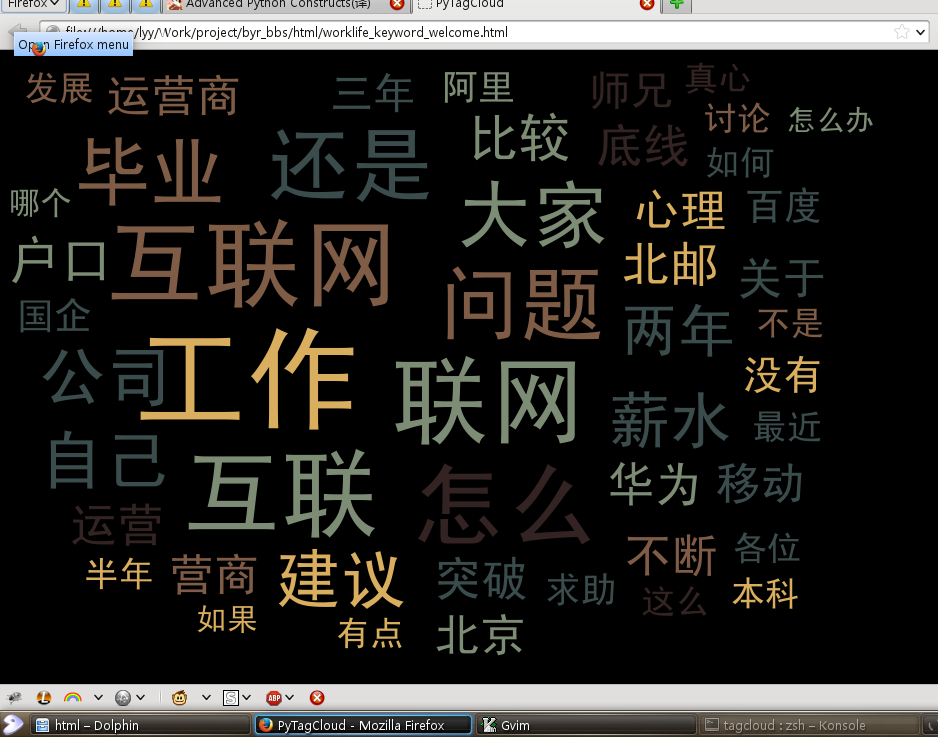
That’s all. 有兴趣的同学可以自行封装以便自己使用。
可能永远不会实现的碎碎念
大概不会有机会了
2014.1.29
利用热度和标题正文数据可以分析下什么样的帖子更容易被回复,试着用bayes方法看看。可以做做内容聚类,主题模型分析。
想起github上一本叫 Bayes Probablistic Programming for Hackers .不知道有空看没