愿总有阳光照进回忆里:学生购电用电查询系统
感冒了,难得会被人挂念。谢谢,总有阳光照进回忆里,温暖的气息让人难以忘记。
某天,一位大神师兄 @Zhaoking 神秘兮兮地给我看一个网站 http://ydcx.bupt.edu.cn/
师兄说,你可以试着把它的数据爬下来。
当时开着八个线程跟着机器学习、回归分析、统计推断、探索性图形分析一堆数据分析的课程,觉得似乎把用电数据爬下来可以玩玩。
于是谨听师兄命令……
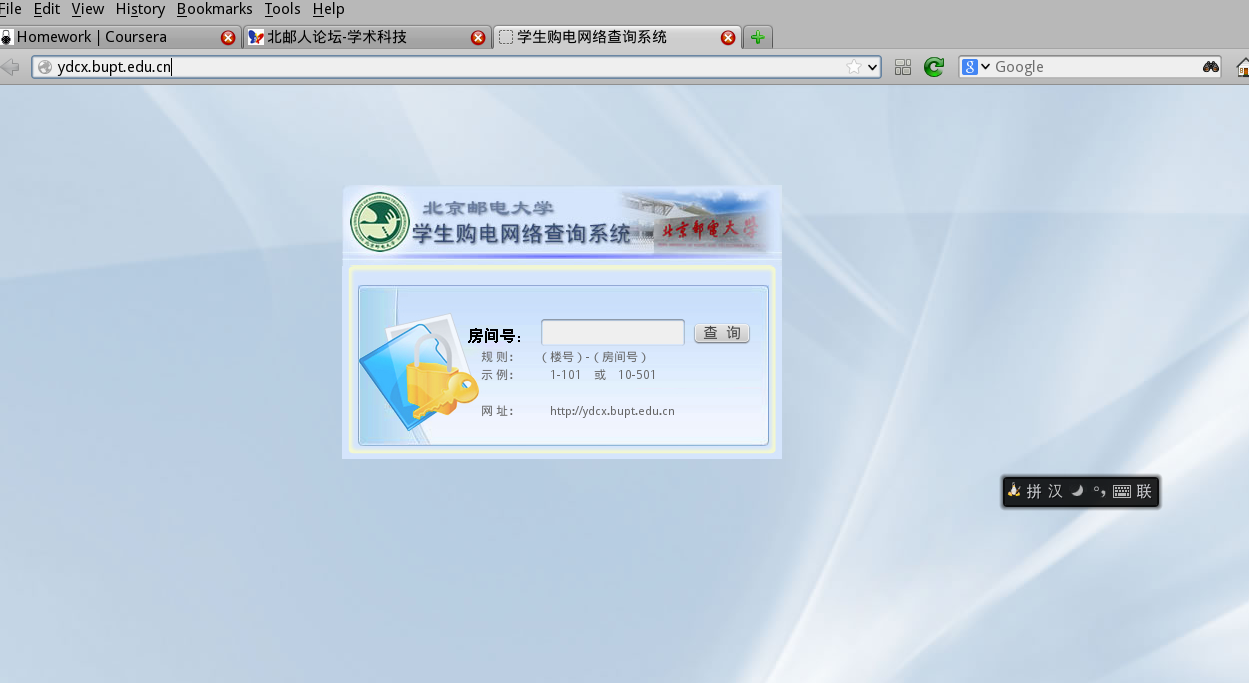
首先,就是研究研究网站逻辑。打开firebug,输入1-101,回车。
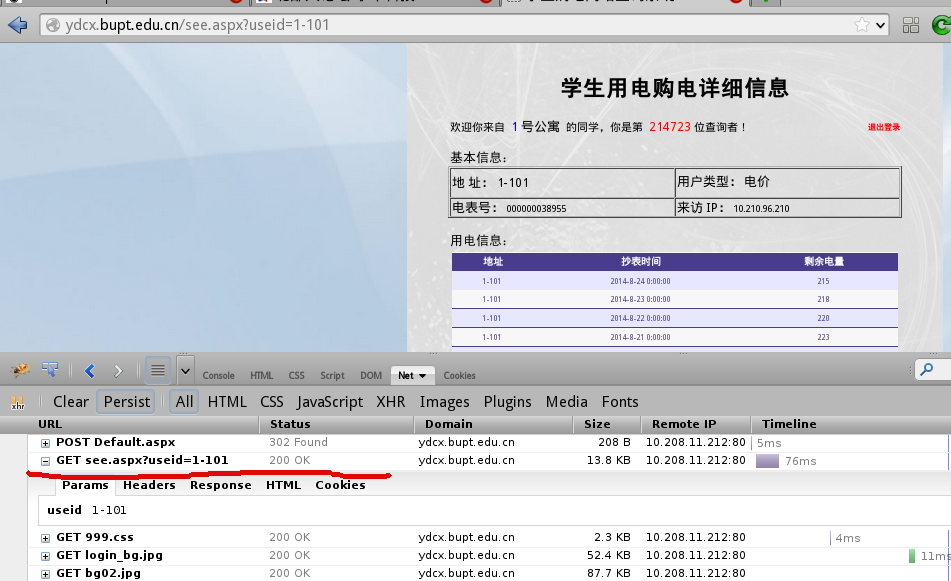
显然,首先是一个post操作,但返回了一个302重定向,所以,第二个请求应该是正确的请求
试试看看
In [1]: import requests
In [2]: dorm_num = '1-101'
In [3]: r = requests.get('http://ydcx.bupt.edu.cn/see.aspx?useid=' + dorm_num)
检查下r.content,确认在里头看到了电量和加电信息。
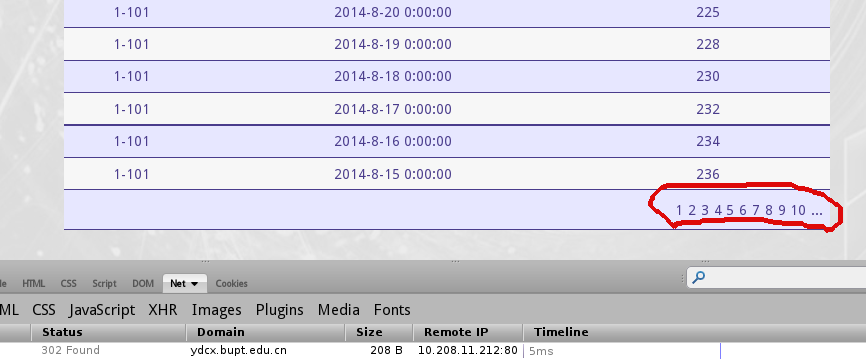
那么,还有这么多页这么办?我们点点看看。页码1已经不能点了,点2。
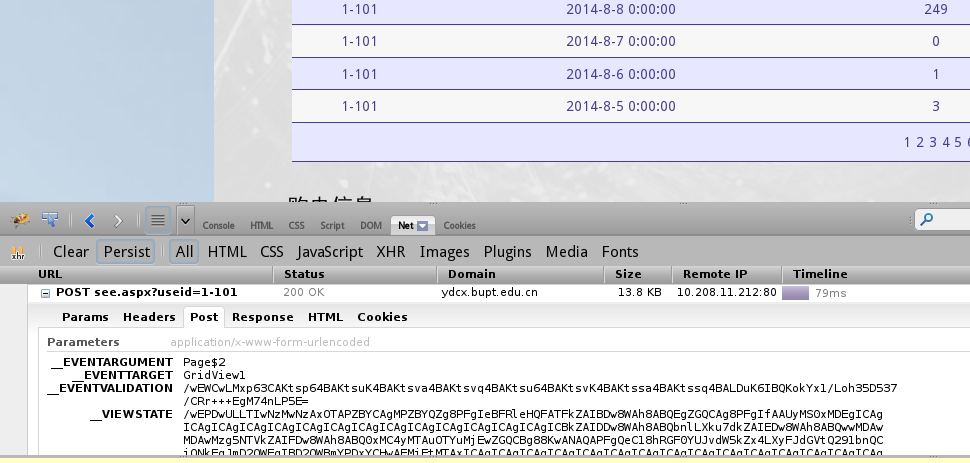
竟然变成一个post了,而且post的数据这么多,你可以抱着试试看的心理不加上这些post的数据试试。
In [5]: __EVENTTARGET = 'GridView1'
In [6]: __EVENTARGUMENT = 'Page$2'
In [7]: data = {'__EVENTTARGET': __EVENTTARGET, '__EVENTARGUMENT': __EVENTARGUMENT}
In [9]: r = requests.post('http://ydcx.bupt.edu.cn/see.aspx?useid=' + dorm_num, data=data)
In [10]: r
Out[10]: <Response [500]>
500——internal error……这个错误一般表示服务器内部处理出现错误。怎么回事呢,直觉告诉我们,问题就在于那些Post的参数。
加上试试,
In [15]: data = {'__EVENTTARGET': __EVENTTARGET, '__EVENTARGUMENT': __EVENTARGUMENT, '__EVENTVALIDATION': '/wEWCwLMxp63CAKtsp64BAKtsuK4BAKtsva4BAKtsvq4BAKtsu64BAKtsvK4BAKtssa4BAKtssq4BALDuK6IBQKokYx1/Loh35D537/CRr+++EgM74nLP5E=', '__VIEWSTATE': '/wEPDwULLTIwNzMwNzAxOTAPZBYCAgMPZBYQZg8PFgIeBFRleHQFATFkZAIBDw8WAh8ABQEgZGQCAg8PFgIfAAUyMS0xMDEgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICBkZAIDDw8WAh8ABQbnlLXku7dkZAIEDw8WAh8ABQwwMDAwMDAwMzg5NTVkZAIFDw8WAh8ABQ0xMC4yMTAuOTYuMjEwZGQCBg88KwANAQAPFgQeC18hRGF0YUJvdW5kZx4LXyFJdGVtQ291bnQCjQNkFgJmD2QWFgIBD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTI0IDA6MDA6MDBkZAICDw8WAh8ABQMyMTVkZAICD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTIzIDA6MDA6MDBkZAICDw8WAh8ABQMyMThkZAIDD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTIyIDA6MDA6MDBkZAICDw8WAh8ABQMyMjBkZAIED2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTIxIDA6MDA6MDBkZAICDw8WAh8ABQMyMjNkZAIFD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTIwIDA6MDA6MDBkZAICDw8WAh8ABQMyMjVkZAIGD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTE5IDA6MDA6MDBkZAICDw8WAh8ABQMyMjhkZAIHD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTE4IDA6MDA6MDBkZAICDw8WAh8ABQMyMzBkZAIID2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTE3IDA6MDA6MDBkZAICDw8WAh8ABQMyMzJkZAIJD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTE2IDA6MDA6MDBkZAICDw8WAh8ABQMyMzRkZAIKD2QWBmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTE1IDA6MDA6MDBkZAICDw8WAh8ABQMyMzZkZAILDw8WAh4HVmlzaWJsZWhkZAIIDzwrAA0BAA8WBB8BZx8CAgVkFgJmD2QWDgIBD2QWDmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAURMjAxNC04LTcgMTQ6MTM6NDBkZAICDw8WAh8ABQMyNTBkZAIDDw8WAh8ABQMxMjBkZAIEDw8WAh8ABQfotK0g55S1ZGQCBQ8PFgIfAAUM5Yqg55S15a6M5oiQZGQCBg8PFgIfAAUJ5byg6ICB5biIZGQCAg9kFg5mDw8WAh8ABTIxLTEwMSAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIGRkAgEPDxYCHwAFETIwMTQtMi0xOCA4OjI3OjQ2ZGQCAg8PFgIfAAUDMjgwZGQCAw8PFgIfAAUBMGRkAgQPDxYCHwAFB+WFjSDotLlkZAIFDw8WAh8ABQzliqDnlLXlrozmiJBkZAIGDw8WAh8ABQnlvKDogIHluIhkZAIDD2QWDmYPDxYCHwAFMjEtMTAxICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGQCAQ8PFgIfAAUQMjAxMy05LTMgOTo1NTowOGRkAgIPDxYCHwAFAzI4MGRkAgMPDxYCHwAFATBkZAIEDw8WAh8ABQflhY0g6LS5ZGQCBQ8PFgIfAAUM5Yqg55S15a6M5oiQZGQCBg8PFgIfAAUJ5byg6ICB5biIZGQCBA9kFg5mDw8WAh8ABTIxLTEwMSAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIGRkAgEPDxYCHwAFEjIwMTMtMy0yMCAxNjozMzoyNWRkAgIPDxYCHwAFAzE4MGRkAgMPDxYCHwAFATBkZAIEDw8WAh8ABQflhY0g6LS5ZGQCBQ8PFgIfAAUM5Yqg55S15a6M5oiQZGQCBg8PFgIfAAUJ5byg6ICB5biIZGQCBQ9kFg5mDw8WAh8ABTIxLTEwMSAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIGRkAgEPDxYCHwAFETIwMTMtMy0xIDE1OjM5OjIxZGQCAg8PFgIfAAUDMTAwZGQCAw8PFgIfAAUBMGRkAgQPDxYCHwAFB+WFjSDotLlkZAIFDw8WAh8ABQzliqDnlLXlrozmiJBkZAIGDw8WAh8ABQnlvKDogIHluIhkZAIGDw8WAh8DaGRkAgcPDxYCHwNoZGQYAgUJR3JpZFZpZXcyDzwrAAoBCAIBZAUJR3JpZFZpZXcxDzwrAAoBCAIoZG6dKHZt7NdjJRdl8NOMCRx8QVCP'}
In [16]: r = requests.post('http://ydcx.bupt.edu.cn/see.aspx?useid=' + dorm_num, data=data)
In [17]: r
Out[17]: <Response [200]>
成功的返回了需要的用电数据,你可以检查下r.content看看
接下来的问题在于,这些参数从哪里来的?
简单谷歌下和检查下网页源代码,可以看到
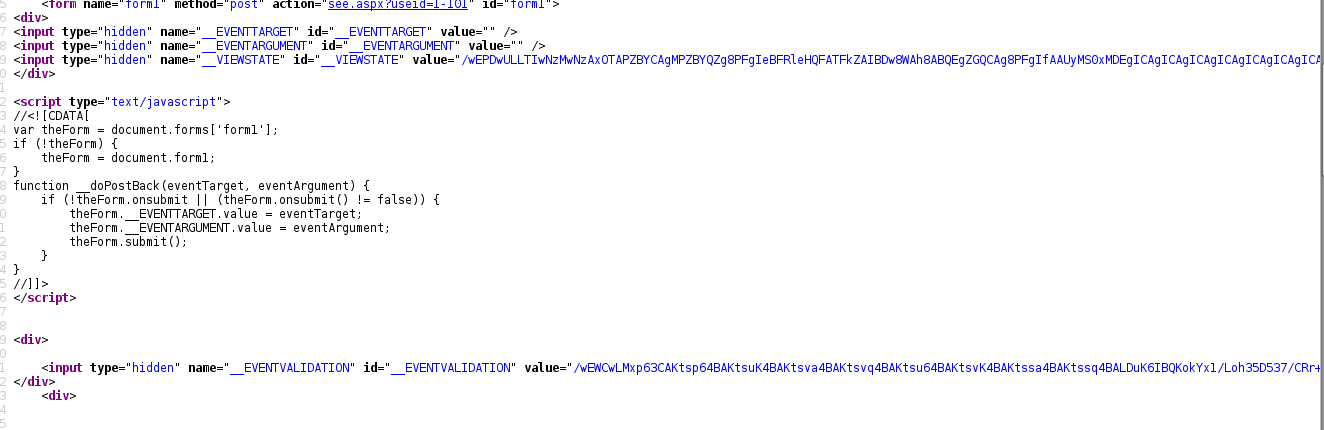
那么逻辑就清晰了,先get请求某个寝室的页面,获取对应的post参数,然后一页一页往后翻就是。
下面讲讲如何从html源码中提取信息,用re当然可以,但是xpath这种东西也许更好用。比如
1 | ## parse the content |
相比写这么个正则简单优雅很多,不过所谓quick and dirty,不管黑猫白猫……:
1 | re.search('id="__VIEWSTATE" value="([^"]+)", r.content).group(1) |
接下来的问题在于,页码总数我不知道,最后的一个…符号可以进入下一个十页。
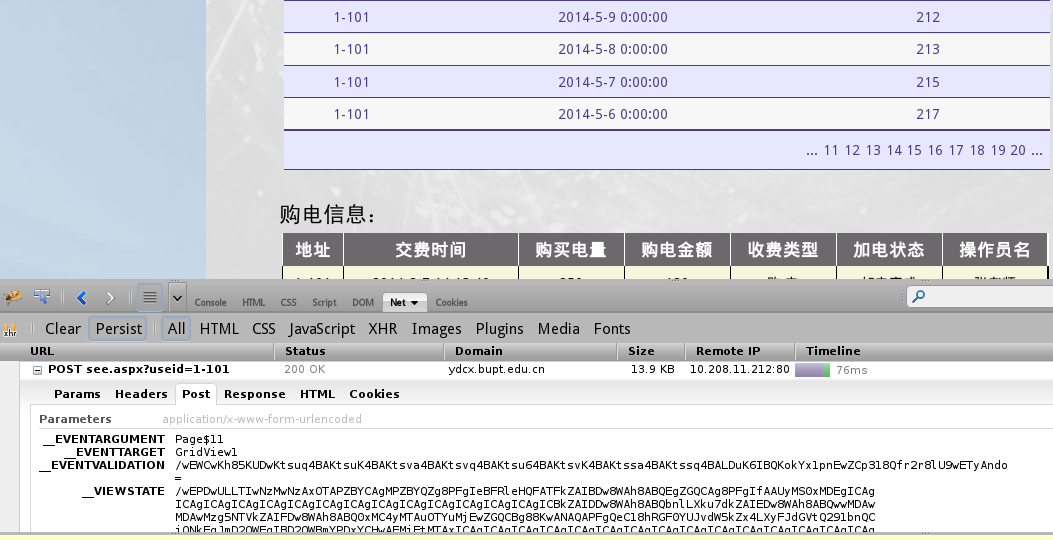
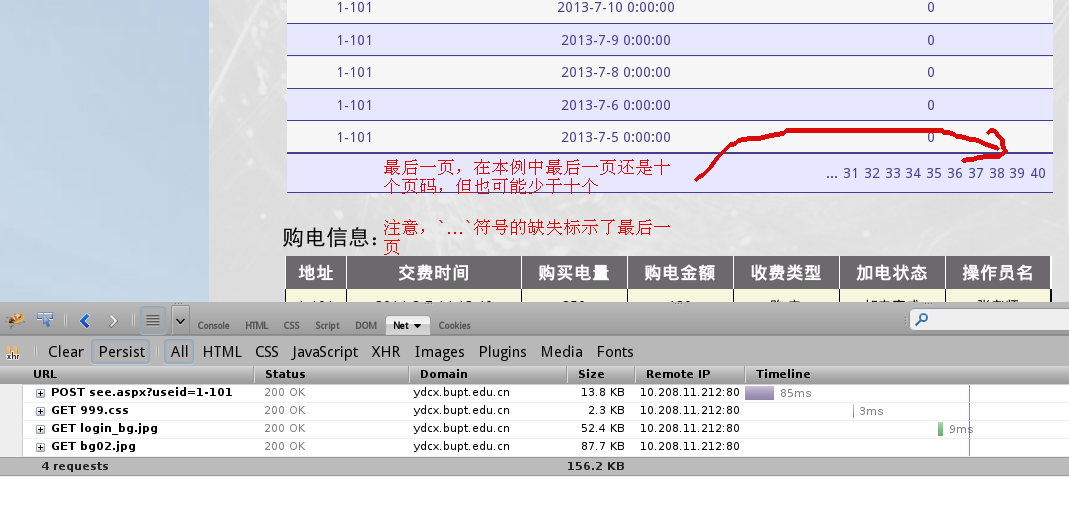
那么,反正最后经过trial and error以一种很quick and dirty的方式work around页码这个问题……
我的解决方案,一个循环,页码不断加一,并且读取当前页右下角所有显示页码。
如果当前页面的那些页码cpn中最后一个,比我下一个想要抓取的np页码小一,或者当前页码个数不是十个,就肯定是最后几页了,就可以抓取然后break不继续往后抓取了。
if (int(cpn[-1]) == np - 1) or (int(cpn[-1]) % 10 != 0):
反正……最后可以运行……
多么不堪入目的实现,随便看看玩
1 | #!/usr/bin/env python |