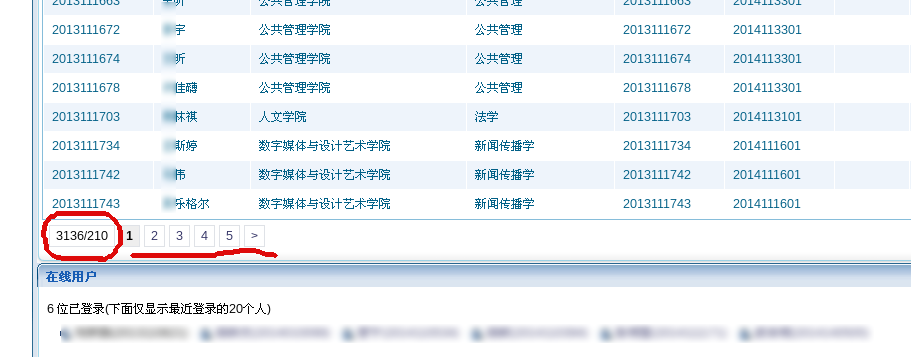
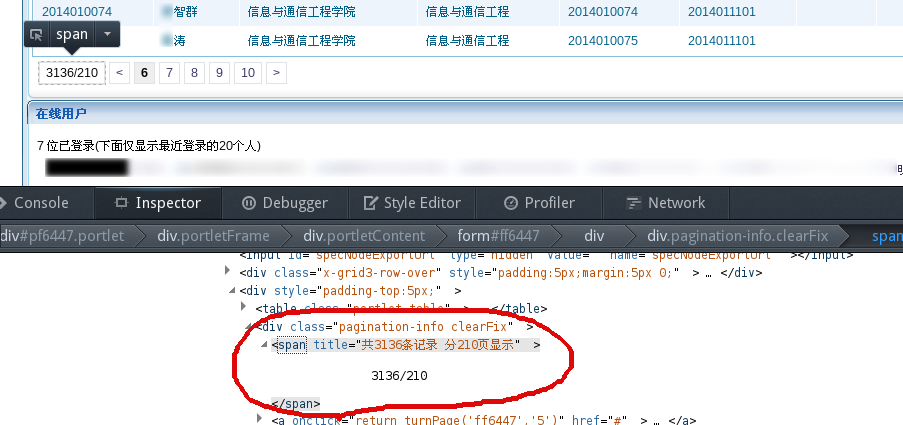
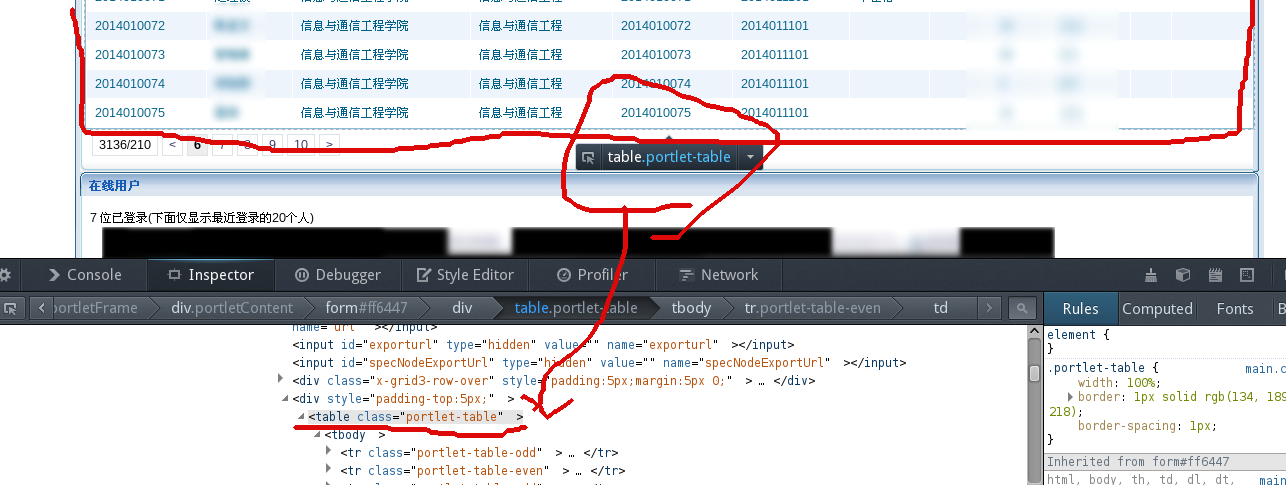
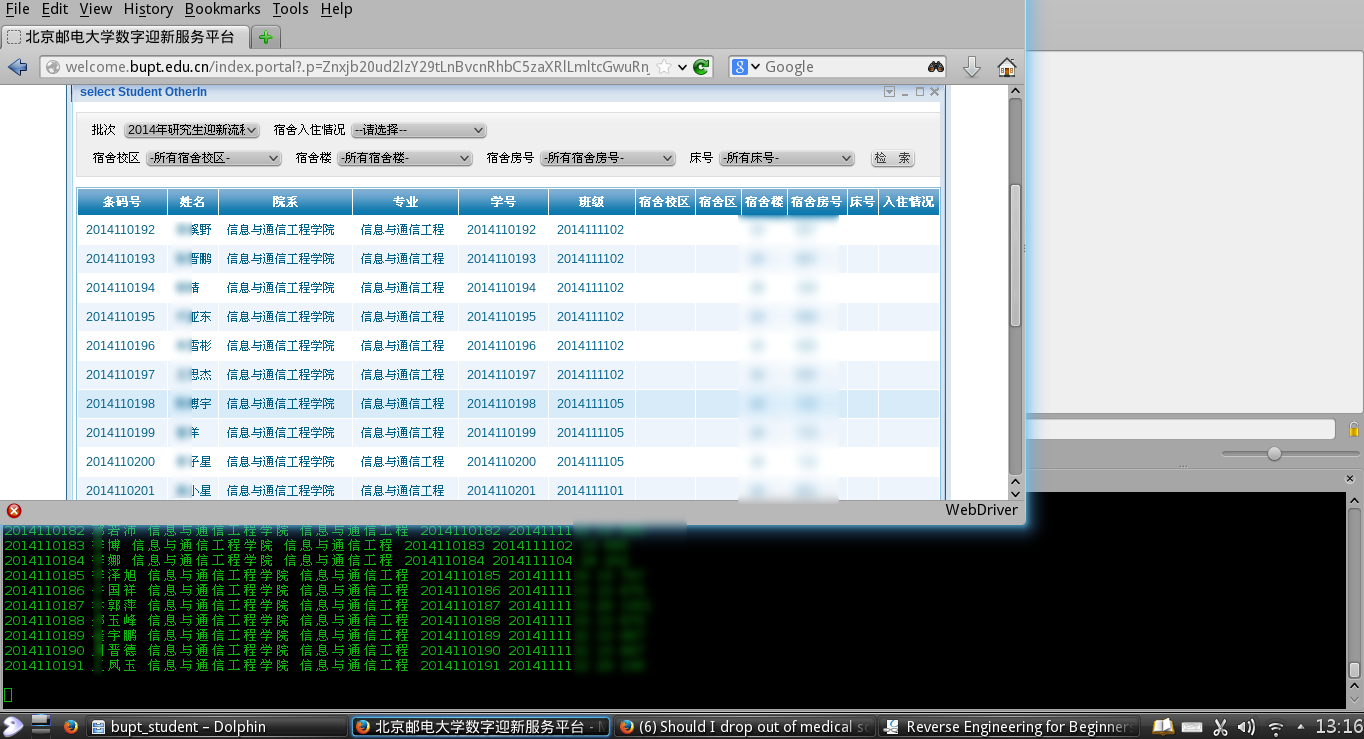
# login success # y p = 1 xpath_p_last = '//div[@class="pagination-info clearFix"]/span' n_pages = driver.find_element_by_xpath(xpath_p_last) p_last = int(n_pages.text.split('/')[1]) n_student = int(n_pages.text.split('/')[0]) print"Number of Students Found: ", n_student while (p <= p_last): time.sleep(random.randint(3, 5)) table = driver.find_element_by_class_name("portlet-table") # remove headers text = table.text[45::] + '\n' print text with open("bupt_students_yan.txt", 'a') as f: f.write(text.encode('utf-8')) p += 1 if p > p_last: print"finished" break if p % 5 == 1: driver.find_element_by_link_text(">").click() else: driver.find_element_by_link_text(str(p)).click()
# b option = driver.find_element_by_xpath('//select/option[@value="serieN10B"]') option.click() p = 1 xpath_p_last = '//div[@class="pagination-info clearFix"]/span' n_pages = driver.find_element_by_xpath(xpath_p_last) p_last = int(n_pages.text.split('/')[1]) n_student = int(n_pages.text.split('/')[0]) print"Number of Students Found: ", n_student while (p <= p_last): time.sleep(random.randint(3, 5)) table = driver.find_element_by_class_name("portlet-table") # remove headers text = table.text[45::] + '\n' print text with open("bupt_students_ben.txt", 'a') as f: f.write(text.encode('utf-8')) p += 1 if p > p_last: print"finished" break if p % 5 == 1: driver.find_element_by_link_text(">").click() else: driver.find_element_by_link_text(str(p)).click()