Python Spider: 爬取百度音乐
2015-04-02
|
Liu Yuyang
|
python
Take a sad song, and make it better:爬取百度音乐
以下,个人的一个trial and error的过程,仅供参考。
用到一些基本知识比如HTTP请求啊,html啊,json啊,ajax啊,当然,不懂也没关系……
使用了一些工具比如firefox啊,firebug啊,python啊……当然你们喜欢用chrome/chromium还是IE都一样……
也许是我听的歌太小众了,经常会发现有些歌在线听的好好的,竟然没有下载链接
 ]
]
对此,很不理解,在线可以听到就说明浏览器已经把媒体文件下载下来并且播放出来了……为啥会告诉我没有下载链接?
某天,听到Beatles的Hey Jude,我忽然觉得得动手找找音乐文件是哪里的。于是,打开firebug,选择network标签下的media标签,可是什么也没有。
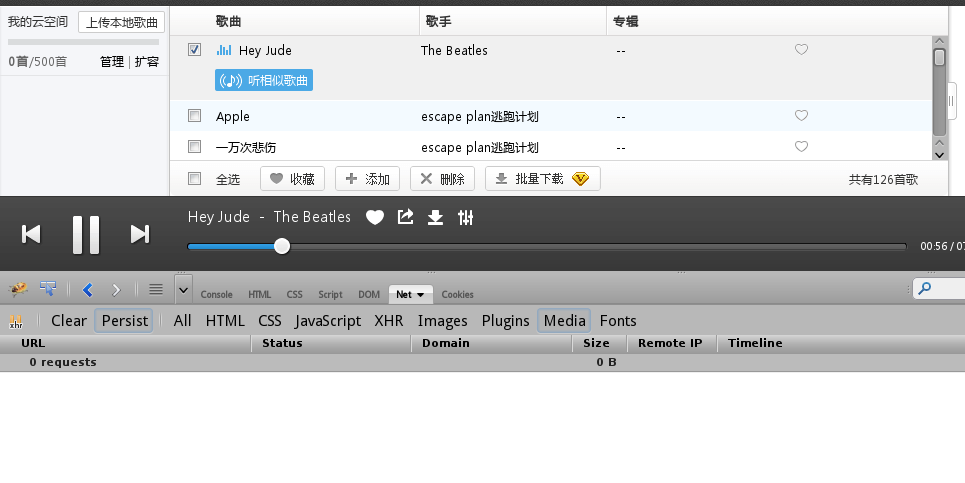
唉?于是又确认了下,百度音乐在线播放器不是flash,满满的html5标签= =
凭借直觉,应该和xmlhttprequest有关系,于是抱着试试看的心理打开firebug上的xhr标签
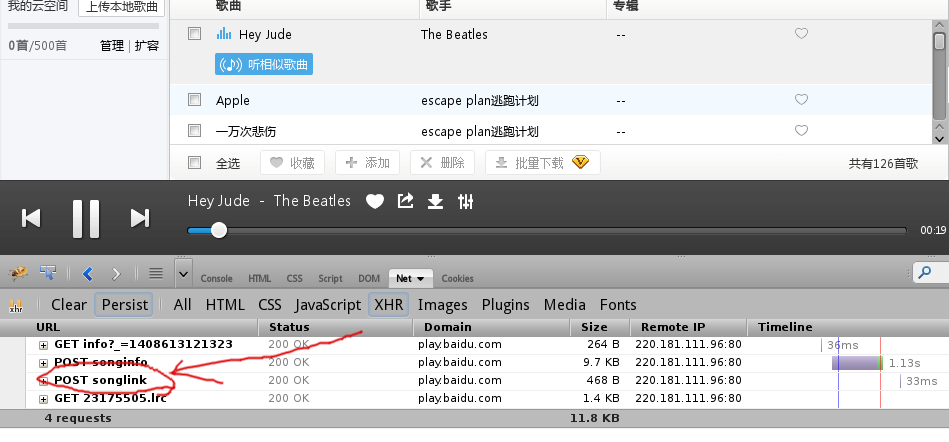
哇,果然有好多请求,咦?songlink?凭借直觉似乎是音乐链接地址……
打开返回的json看了看果然有个来自file.qianqian.com的疑似歌曲链接(有时候用firebug的搜索功能也不失为良策)……

把引号中的链接复制粘帖到地址栏,哇,果然是歌曲mp3啊
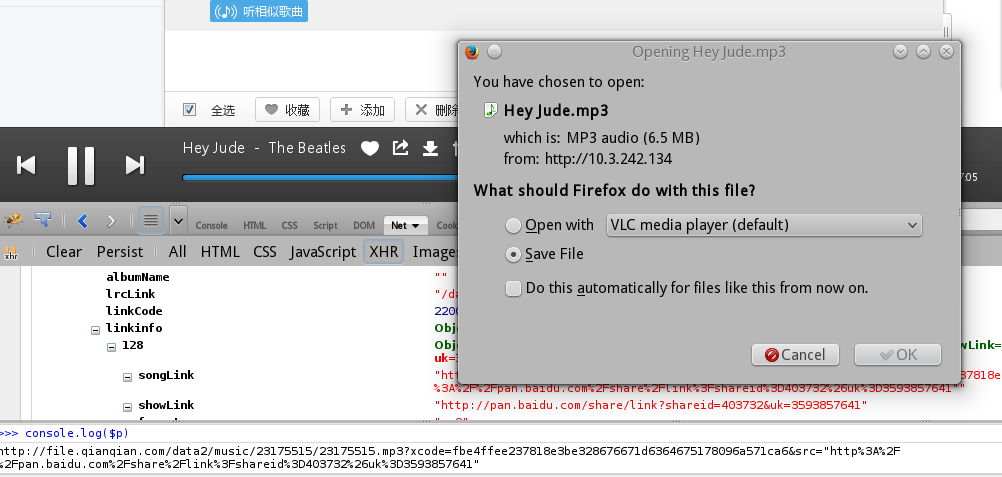
我们可以再认真看看返回的json,其中有lrc歌词链接,有封面图片链接、歌曲文件大小啊等等
接下来的问题是,如果想下载其它歌曲怎么办。首先观察之前我们获取想要mp3链接的POST请求。
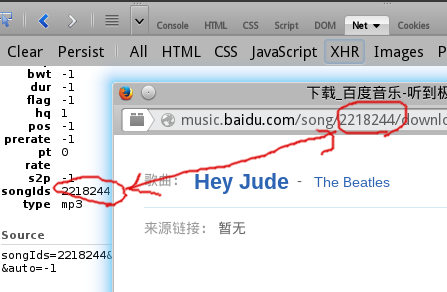
请求参数中有一个songID?似乎很清晰的样子,我猜吧,每个歌曲在百度音乐库中都对应这么一个ID
后来发现确实差不多。
至此,可以开始写自己的爬虫了……
关键部分大致这样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def download_by_song_id_list(song_id_list):
song_data = 'songIds=' + "%2C".join(song_id_list)
song_link_url = "http://play.baidu.com/data/music/songlink"
headers = {"X-Requested-With": "XMLHttpRequest",
"Content-Type": "application/x-www-form-urlencoded;\
charset=UTF-8"}
r = requests.post(song_link_url, data=song_data, headers=headers)
data = json.loads(r.content)
for it in data['data']['songList']:
print '\n' + it['songName'], ': ', it['size'], "bytes"
r_song = requests.get(it['songLink'], stream=True)
with open(it['songName'] + '.' + it['format'], 'wb') as f:
dl = 0
total_length = int(it['size'])
for b in r_song.iter_content():
if not b:
break
dl += len(b)
f.write(b)
done = int(50 * dl / total_length)
sys.stdout.write("\r[%s%s] %.2f%%"
% ('=' * done, ' '
* (50 - done), 100.0 * dl / total_length))
sys.stdout.flush()
print '\n' + it['songName'] + '.' + it['format'], " finished"
|